Video Activity Localisation with Uncertainties in Temporal Boundary
Accepted by European Conference on Computer Vision (ECCV'22)
Queen Mary University of London
The goal of video activity localisation is to locate temporally video moments-of-interest (MoIs) of a specific activity described by a natural language query of an untrimmed continuous long video (often unscripted and unstructured) that contains many different activities.
Existing video activity localisation solutions either adopt a proposal-free paradigm to predict directly the start and end frames of a target moment that align to the given query, or a proposal-based paradigm to generate many candidate proposals for a target moment and aligns segment-level video features with the query sentences. The proposal-free methods deploy directly the fixed manual activity endpoints labels for model training, implicitly assuming these labels are well-defined. However, there is a considerable variation in how activities occur in unconstrained scenarios, i.e., the manual temporal labels are inherently uncertain and prone to significant misinformation. On the other hand, by formulating the localisation task as a matching problem, the proposal-based methods consider alignment by the whole moment with less focus on the exact boundary matching. Therefore, it can be less sensitive to the boundary labels but more reliance on salient content. Nonetheless, the problem of detecting accurately the start and end-point of a target activity moment remains unsolved.
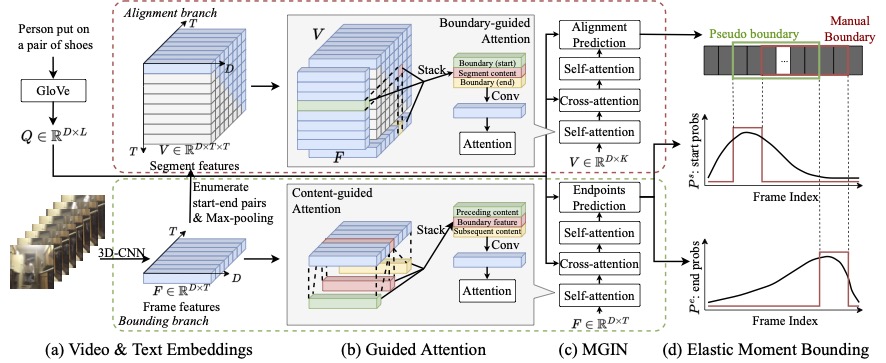
In this work, we introduce Elastic Moment Bounding (EMB) to address the limitation of proposal-free paradigm by modelling explicitly label uncertainty both in training and testing. The key idea is that, considering the uncertain nature of activity temporal boundary, it is more intuitive to represent the endpoints of video activity by temporal spans rather than specific frames. To that end, the EMB model conducts a proposal-based segment-wise content alignment in addition to learning of frame-wise boundary identification. As the predicted segment is required to be highly aligned with the query textual description, we represent the gap between the predicted endpoints and the manually labelled endpoints as an elastic boundary to enable optimal endpoints selection to be consistent in semantically similar video activities.
Our contributions are: (1) We introduce a model to explore collaboratively both proposal-free and proposal-based mechanisms for learning to detect more accurate activity temporal boundary localisation when training labels are inherently uncertain. We formulate a new Elastic Moment Bounding (EMB) method to expand a manually annotated single pair of fixed activity endpoints to an elastic set. (2) To reinforce directly robust content matching (the spirit of proposal-based) as a condition to accurate endpoints localisation (the spirit of proposal-free) of activities in videos, we introduce a Guided Attention mechanism to explicitly optimise frame-wise boundary visual features subject to segment-wise content representations and vice versa. (3) Our EMB model provides a state-of-the-art performance on three video activity localisation benchmark datasets, improving existing models that suffer from sensitivity to uncertainties in activity training labels.
Please kindly refer to the paper for more details and feel free to reach me for any question.