Deep Semantic Clustering by Partition Confidence Maximisation
Accepted by IEEE Conference on Computer Vision and Pattern Recognition (CVPR'20)
Queen Mary University of London
Description
Deep Clustering, which jointly optimises the objectives of representation learning and clustering with the help of deep learning techniques, is proposed to address the limitation of traditional cluster analysis algorithms when dealing with high-dimensional imagery data with indiscriminative visual representations. Although conducting cluster analysis with learnable representations holds the potential to benefit clustering on unlabelled data, how to improve the semantic plausibility of these clusters remains an open problem.
Recent deep clustering models either iteratively estimate cluster assignment and/or inter-sample relations which are then used as hypotheses in supervising the learning of deep neural networks, or used in conjunction with cluster constraints. The alternate training strategy is susceptible to error-propagation due to inaccurate membership estimation. The simultaneous one, which usually supervised by pretext tasks that require good cluster structure, suffers from the vague connection between training supervision and cluster objectives. Without global solution-level guidance to select from all the possible separations, the resulted clusters tend to be semantically less plausible.
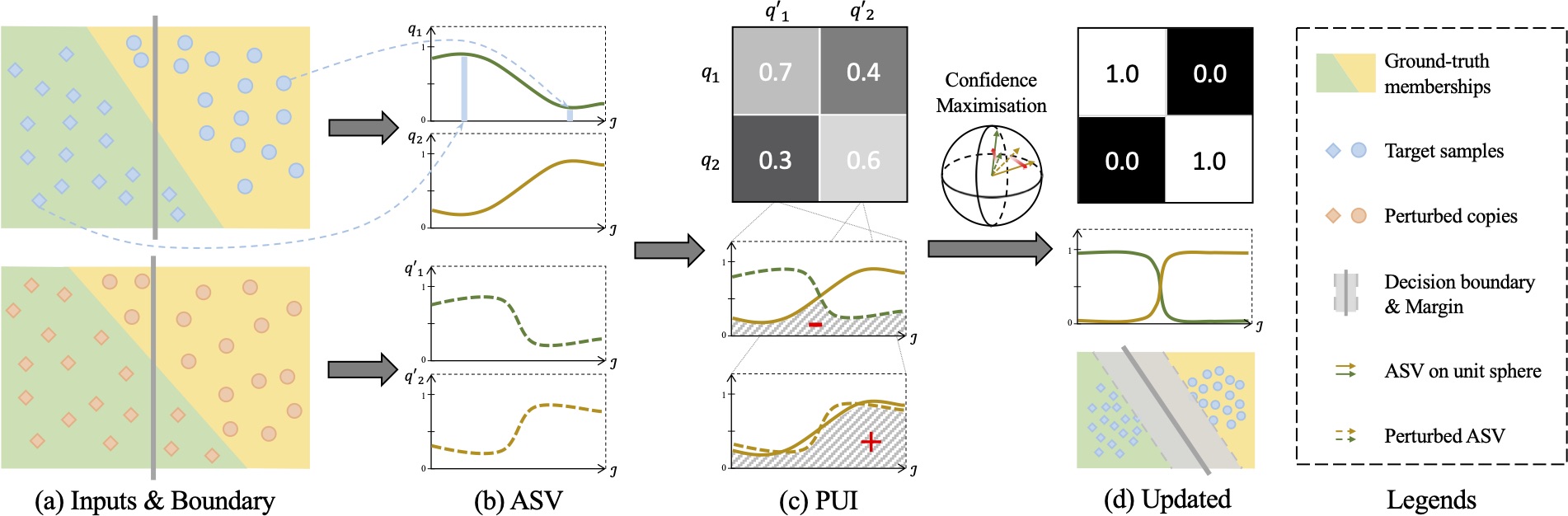
In this work, we propose a deep clustering method called PartItion Confidence mAximisation (PICA). Due to the high visual similarity shared by samples from the same semantic classes, assigning them into different clusters will reduce the resulted intra-cluster compactness and inter-cluster diversity, i.e. lower partition confidence. Based on this insight, PICA is designed to encourage the model to learn the most confident clusters from all the possible solutions in order to find the most semantically plausible inter-class separation. This is in spirit of traditional maximal margin clustering which also seeks for most separable clustering solutions with shallow models (e.g. SVM), but differs notably in that both the feature representations and decision boundaries are end-to-end learned in our deep learning model. Specifically, a partition uncertainty index (PUI) is proposed to quantifies how confidently a deep model can make sense and separate a set of target images. A stochastic approximation of PUI is introduced to enable standard mini-batch based learning and a novel objective loss function is formulated for training with any off-the-shelf networks.
Our contributions are threefold:
- We propose the idea of learning the most semantically plausible clustering solution by maximising partition confidence, which extends the classical maximal margin clustering idea to the deep learning paradigm.
- We introduce a novel deep clustering method, called PartItion Confidence mAximisation (PICA) which is built upon a newly introduced partition uncertainty index that is designed elegantly to quantify the global confidence of the clustering solution.
- A stochastic approximation of the partition uncertainty index is formulated to decouple it from the whole set of target images, therefore, enabling a ready adoption of the standard mini-batch model training.
Benchmarks
Extensive experiments are conducted on six challenging objects recognition benchmarks which demonstrates the advantages of PICA over a wide range of the state-of-the-art approaches.
- CIFAR10(/100): A natural image dataset with 50,000/10,000 samples from 10(/100) classes for training and testing respectively.
- STL10: An ImageNet sourced dataset containing 500/800 training/test images from each of 10 classes and additional 100,000 samples from several unknown categories.
- ImageNet-10 and ImageNet-Dogs: Two subsets of ImageNet: the former with 10 random selected subjects and the latter with 15 dog breeds.
- Tiny-ImageNet: A subset of ImageNet with 200 classes. There are 100,000/10,000 training/test images evenly distributed in each category.
Please kindly refer to the paper for more details and feel free to reach me for any question.